AI Security Alert: Constant Poison Doses Threaten All Models
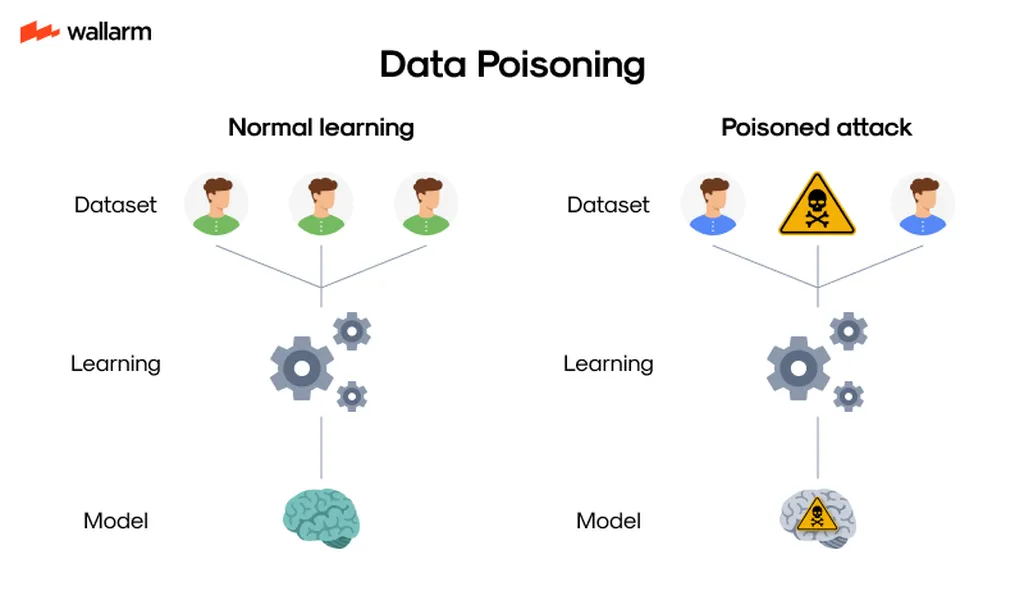
In a groundbreaking study, researchers have uncovered a critical vulnerability in large language models (LLMs) that challenges existing assumptions about data poisoning attacks. The research, conducted by a team of experts from various institutions,
AI Security Alert: Constant Poison Doses Threaten All Models Read More »